Engine Work
Sunday, November 19th, 2023
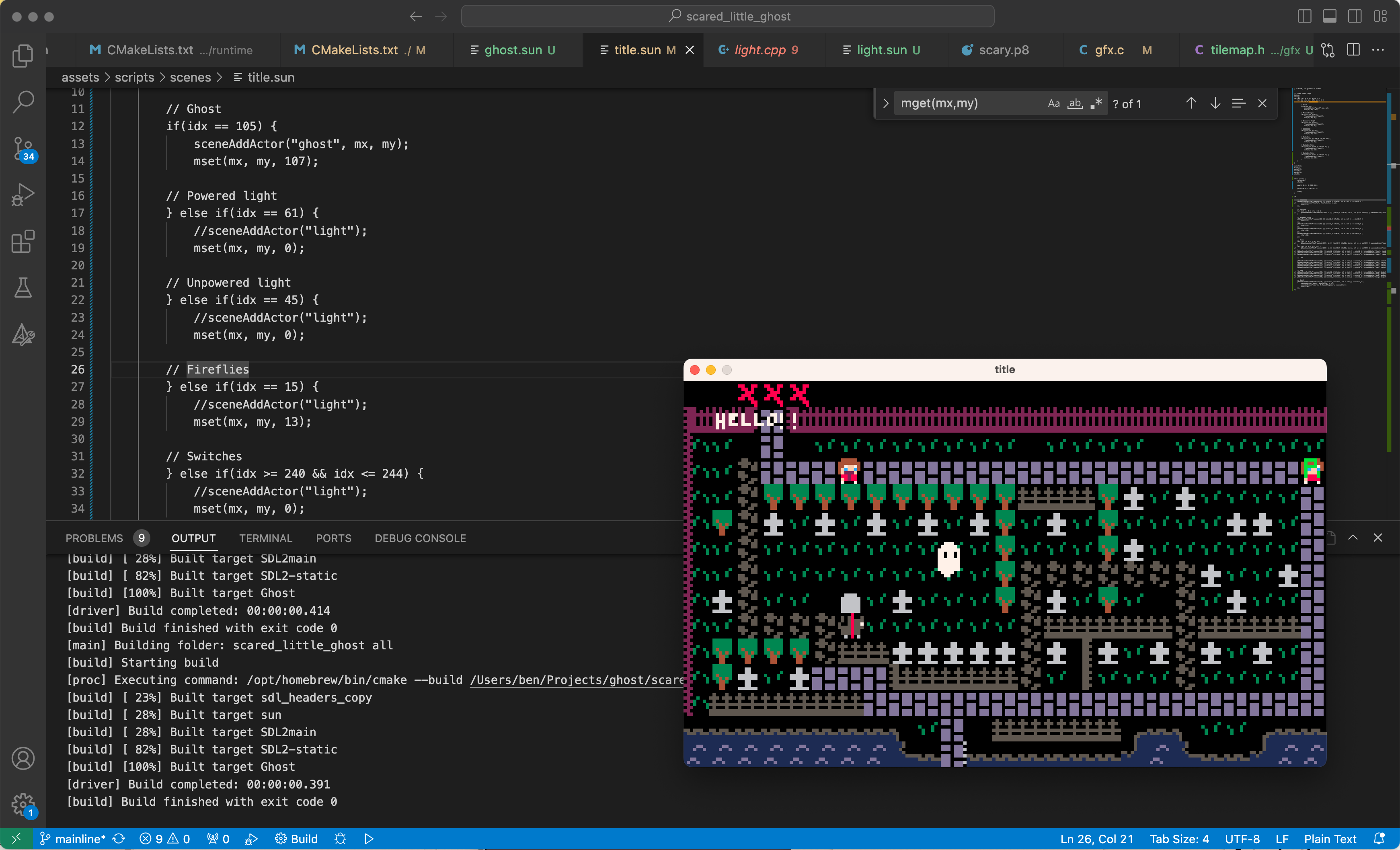
So over on Cohost I threatened to make a big post about it and now I'm making good on my threat. Here's the "Where I'm up to now with the Scared Little Ghost custom engine and some details about how it works" big post.
Introduction
So to explain the game, Scared Little Ghost is a PICO-8 game I started back in 2022 which folks seemed to like. I took it to Tokyo Sandbox and showed it to the public and released that demo a few times on Itch.io.
The game is a non-violent, exploration stealth game where you're a ghost who is afraid of everything. You travel around a graveyard talking to cats and avoiding ghost hunting teenagers. Over the course of the game... well... perhaps I won't spoil it too much. 😂
Making the game in PICO-8 had its advantages - I got to focus more on the design, the aesthetics were informed by the limitations of the system, and I got a lot of work done. However, the limitations of the environment also started to make it harder to work on the game as it grew, and I couldn't add the additional features I wanted to in order to make the game world richer. One of the things I found in making the game non-violent is that the game world itself needs a lot of content to add challenge and interest. If you're not aware, PICO-8 has both a code token (operation) limit, as well as a limit on the size of the cartridge if you want to distribute builds. I managed to make the Tokyo Sandbox demo within those limits, but it was tight. I also added a Japanese translation into the same build which was challenging to do, and required some special tools I had to build. Basically, my work became more about overcoming the limitations of PICO-8 and less about making tools and content that forwarded the game.
So I decided it was time to port it to something.
Why A Custom Engine?
I don't know. 😂 Well, I do. But it's not a decision I took lightly.
I've worked on in-house engines before, Steel Diver used an in-house engine, and I also built a few other prototypes over the years. So it wasn't something that I couldn't do, but at the same time I understand the overheads. However, I had some things I wanted to aim for with a port, which is why I eventually went with a custom engine; these being:
- A software renderer
- Low file size and memory usage
OK, basically just that? But it's kind of an interesting challenge because most game engines already available have lots of features, and are generally designed to run with hardware accelerated pipelines. Which is fine. But not what I wanted.
At the end of the day, I just decided I'd hack apart some of my old work and make what I wanted.
Design
Scared Little Ghost is, technically speaking, a fairly simple game. It's a bunch of sprites on a tile map, some A* pathfinding, no physics, no streaming world. So it's fairly light in terms of needing to manage resources. So I decided to opt for the classic 'load everything in a scene up-front' approach.
For the structure of the game I decided to use a scenes and actors style approach. Scenes would be defined by data files detailing what is used in each. Then actors would represent individual game entities, optionally having a script for logic. This approach is similar to how other engines work, but is less complex than something like an ECS. (Interestingly though, you can mimic the behaviour of an ECS using a system like this, defining shared functions called by each script to perform shared behaviour patterns. It's just less flexible.)
I also wanted (as I generally try to) to make the components of the engine interchangeable. Not ... flexible, as a general purpose engine might be, but something I could strip out and use either in another project or replace. But all this in moderation. 😆
Base Tools & Libraries
I wanted to write the base 'engine' logic in C (as opposed to C++ etc.) as I find it a lot easier to reason about memory and simpler to work with.
For this project I built off these tools:
- SDL for video management, mainly because it has good support for software rendering already.
- STB, for a whole bunch of image loading and font loading implementations.
- PhysFS for file loading so I can distribute the game with a compressed data 'pak' rather than a filesystem.
- Parson, a C JSON parser.
- PCG Random Number Generator for a cross-platform random number algorithm.
I also used Aseprite for images and kept PICO-8 around for porting. And, for building, I decided to use CMake.
Memory
For the structure of the game, let's start with memory.
The game is written using arena allocators. Basically, a chunk of memory that I ask the OS for ahead of time.
Here's an example API:
extern MemoryArenaID kSystemMemory;
extern MemoryArenaID memoryArenaCreate(MemoryArenaID hostArena, size_t size);
extern void memoryArenaPushWatermark(MemoryArenaID arena);
extern void memoryArenaPopWatermark(MemoryArenaID arena);Basically, you can make arenas from system memory, and then (if you want to) subdivide those arenas by allocating arenas inside them. You can watermark arenas, which basically stores how much memory has currently been allocated, and by popping the watermark you basically 'reset' it back to that allocation state.
For allocation, here's another example API:
extern void *_memoryAlloc(MemoryArenaID arena, size_t size, const char *filename, size_t lineNumber);
#define memoryAlloc(arena, size) _memoryAlloc(arena, size, __FILE__, __LINE__)Similar to any malloc implementation, but with an extra parameter for size. (I currently have my allocated defined similarly, one neat thing I want to do in the future is use the file/line information in debug builds to check where is allocating what.)
Using these API you can lay out your memory similarly to this:
| Common resources | Scene-based resources | Actor memory | Unused... | Temporary! |
...where permanent allocation grows from the left to right, the thick black line representing the position at which the next allocation will occur. I haven't currently implemented this, but the temporary memory on the right is probably how I will deal with temporary memory allocations required for things like reading in files, growing from the right means that you can easily overwrite it when it's no longer needed, and you won't leave a giant hole in your allocations to the left.
You will notice there is no free function. To free, you reset the arena back to it's initial state. There is no point in freeing memory here because it leaves a hole:
| Common resources | 'Freed' memory | Actor memory | Unused... |
Of course, you can manage that kind of hole, but it's complicated. (You can read about buddy allocators if you're interested in one way to do this.) I don't need it for my game, so there's no free. It's also much faster as there's no resource tracking and making individual actors free their used resources.
Scenes and Actors
So now memory is sort of out of the way, I can talk about scenes and actors because they're fairly related to how memory works. (We're never leaving memory talk perhaps? 🫠)
Anyhow.
The way I'm doing scenes is not that much different to any other game engine, Unity etc. has scenes. From a data standpoint a scene is, basically, defined as a JSON file like this:
{
"spritesheet": "tilesheet",
"font": "pico-8-mono",
"tilemap": "graveyard",
"actor-definitions": [
"ghost"
],
"script" : "scenes/game"
}...which the game will load and parse using Parson, as described before. From an API standpoint, scenes use something like this:
extern SceneID gameSceneSwitch(MemoryArenaID arena, const char *name);
extern void gameSceneUpdate(SceneID scene);The scene name passed is used to generate the file path, the JSON above is loaded and then memory allocation happens. Conceptually, you can think of scenes as states that can either replace or stack on top of each other. When single scene is in memory, the overall usage might look something like this:
| SFX | Fonts | Game Sprites | Game Map | Game Actors |
But, if you wanted to, for example, go into a menu whilst preserving the state of the game you could (potentially) do something like this:
| SFX | Fonts | Game Sprites | Game Map | Game Actors | Menu Sprites | Menu Actors |
It's a fairly flexible system.
Actors, data-wise, are similar to scenes. They have a JSON:
{
"script" : "actors/ghost"
}And an API:
extern ActorID gameSceneAddActor(SceneID scene, const char *name);Scenes have a list of 'actor definitions' that are loaded up-front when the scene is changed, this is the JSON given above. When the gameSceneAddActor is called, the relevant one is found and used to create a new actor. This means we don't have to load resources when instantiating a new actor for the game.
I'll talk about scripting next, but I also considered using scripts instead of JSON for definition of actors/scenes. I'm undecided, but the lower overhead in having a data format rather than the cost of making everything a script feels like it makes sense. These data files can generally be thrown away, but scripts are longer lived.
Speaking of which...
Remember that there's no free? Well, there are short-lived actors in the game, things like message dialogues and cutscene controllers, things that do have a shorter lifespan that we need to re-use. So for that, the scene has a circular pool of actors that all have the same memory size:
| A1 | A2 | A3 | A4 | ... | A1024 |
We simply load the actor script into the next available actor slot when we need a new one, and when that script stops running it become available again. This has the downside that all actors need the same memory size, but since my scripts are fairly lightweight it should be fine. Hopefully. 😆
Scripting
There are currently two types of script in the game, one for the scene (can be used to load and spawn things outside of data files) and one for actors. For the scripting experience I wanted a language that was...
- Simple
- Able to be compiled ahead of running (for distribution)
- Ideally with a stable memory usage for each instance (to allow the actor table)
- Allowing instances of each script to be used without duplicating the script data
- Able to be suspended at arbitrary points (coroutines/lightweight threading)
I use coroutines a lot for my games, they're super useful and I wish C had native support for them. But it doesn't. (Duff's device doesn't count and longjmp isn't portable, in my experience.)
Pass 1: C++
Unlike C, C++ 20 and later does have support for coroutines. C++ is a compiled language, can be fairly simple if you limit how you use it, and you can use the allocation techniques discussed previously to ensure memory usage is stable. So as a first pass I tried implementing the game with C++ Coroutines.
I got pretty far! Some of the examples I've posted in the past used that version of the code! But... C++ coroutines are... pretty quirky. A good example of that is how to actually allocate the coroutine object itself using a custom allocator. C++ has reasonable support for this, you can pass an address to the new operator to initialise an object in memory you've already allocated, like so:
void *memory = malloc(sizeof(MyObject));
MyObject *o = new(memory) MyObject(...);but! C++ Coroutines don't use new directly, you call them and then they allocate themselves. Like this:
co<bool> coroutine() {
co_yield true;
}
auto output = coroutine();You can override the allocator, but then it becomes difficult to tell which memory arena that the allocator should be using. (It's possible in a few ways, but messy.) Coupled with how difficult I found it to make the coroutine classes in the first place... I decided to scrap C++.
Pass 2: Custom
I looked at the usual (and some unusual) scripting languages that are available, and tried to integrate a few into the game. Some were close to how I wanted to work, but I kept running into a few things with most of them which made me feel like they weren't the right fit.
So I decided to re-visit an old set of projects I worked on in the past and make a simple scripting language. At Vitei I prototyped a language which never saw production, called Moon. The language I've been prototyping for this game (calling it Sun for now... I'll probably change that...) isn't at all similar, but uses a lot of the stuff I learnt making that language. It currently also mimics fairly closely how Pawn works, which is a compiled, register based scripting language designed for embedded systems.
Scripting Language Design
The language of Moon was fairly interesting, and should be pretty friendly for anyone who uses a modern scripting language:
include output
use Base
import printLn(output:string)
shared def main()
printLn("Hello World")
endIt had features like type inference, which was neat.
Sun is a lot simpler (although I am still not finished with the language design). The above example would be written:
printLn("Hello World");Sun scripts are written with the assumption that "one file is one module", do not require main functions, and do not require explicitly importing functions. They currently use a syntax that is much closer to C, with type decoration on all variables:
float time = 0;
while (true) {
time += 1/30;
float ax = 0;
float ay = 0;
if (canMove == false) {
if(btn(@"left"))ax-=1;
if(btn(@"right"))ax+=1;
if(btn(@"up"))ay-=1;
if(btn(@"down"))ay+=1;
}
}It also has first-class support for sleep as a keyword, which will immediately suspend the running script and return to whatever called it:
void runCutscene() {
for (int f = 0; f < 100; f+=1) {
print("I can show you the world...", 10, 10);
sleep;
}
for (int f = 0; f < 100; f+=1) {
print("Shining, shimmering, splendid...", 10, 10);
sleep;
}
}The language itself does not support lightweight threads or coroutines, it is simply suspending the entire execution of that script. The design is very much for scripts to represent one object, and the host environment to implement co-operation.
Scripting Language Compiler
The implementation of the language compiler is fairly involved, but here are the main steps.
The lexer is implemented in Flex. This is an old system for making lexers using a DSL that is translated to C. The syntax looks a bit like this:
%{
#include <sun/tree/node.h>
%}
%%
[0-9]+\.[0-9]+ { *yylval = sltNodeMakeFloat(atof(yytext)); return FLOAT; }
[0-9]+ { *yylval = sltNodeMakeInteger(atoi(yytext)); return INT; }
\"[^\"\n]*\" { *yylval = sltNodeMakeString(yytext); return STRING; }
[a-zA-Z0-9_]+ { *yylval = sltNodeMakeIdentifier(yytext); return IDENTIFIER; }
. { return yytext[0]; }
%%
The parser is written in Bison, which is often paired with Flex (or older variants like Lex) and allows you to make a parser using a DSL, similar to this:
%{
#include <sun/tree/node.h>
%}
%token IDENTIFIER
%token INT
%token FLOAT
%token STRING
%%
arithmetic_expression
: primary_expression
| arithmetic_expression '+' arithmetic_expression {
$$ = sltNodeMakeBinaryOperation(sltNodeMakeOperator(SLTOperatorTypeAdd), $1, $3);
}
| arithmetic_expression '-' arithmetic_expression {
$$ = sltNodeMakeBinaryOperation(sltNodeMakeOperator(SLTOperatorTypeSubtract), $1, $3);
}
| arithmetic_expression '*' arithmetic_expression {
$$ = sltNodeMakeBinaryOperation(sltNodeMakeOperator(SLTOperatorTypeMultiply), $1, $3);
}
| arithmetic_expression '/' arithmetic_expression {
$$ = sltNodeMakeBinaryOperation(sltNodeMakeOperator(SLTOperatorTypeDivide), $1, $3);
}
| arithmetic_expression '%' arithmetic_expression {
$$ = sltNodeMakeBinaryOperation(sltNodeMakeOperator(SLTOperatorTypeModulo), $1, $3);
}
;
primary_expression
: IDENTIFIER
| INT
| FLOAT
| STRING
| '(' expression ')' {
$$ = sltNodeMakeCompound($2);
}
;
%%
The parser takes the input from the lexer, matches that input to the rules you give (this token followed by that token) and then produces a tree that represents the program.
After this process, the tree is further processed to produce a bytecode version of the program. This is pretty complicated, so I won't talk much about how it works, but the main steps are generally:
- Find all the strings used in the program and put them into a string table.
- Scope all the nodes, so you know which functions/variables should be known about at each line of the program.
- Resolve all the names, i.e. with the line
a = 10;find out which variable 'a' is being referred to. This also works out if a function call is referring to a function that is already in the program (in which case the VM will run it) or not (in which case the host program will be asked to run it). - Generate the bytecode instructions (similar to assembly).
The idea is that this compiler can be run either as part of the host program (useful for game development!) or as a separate program. This gives flexibility in how you want to package the game.
Scripting VM
The VM for the bytecode is fairly simple because most of the difficult stuff is being handled at the compilation step. I'll run through how it works.
The bytecode for each script is basically represented as assembly-style instructions, similar to this:
SET 1, 2
SET 2, 3
ADD 1, 1, 2
CALL <sqrt>
MOV -1, 0This would come from a program like this:
float a = sqrt(2+3);To understand how this works, first I'll talk about how the VM executes the code. Each script instance has two stacks (you can do it with one but I'm using two) which represent the current executing context of the script. The stacks combined take up the entirety of the memory allowed for each game script.
A representation of the data stack would look something like this:
| nil | nil | nil | nil | nil | nil | nil | nil | nil | nil | nil | nil | nil | nil | nil |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | -2 | -1 |
The stack locations 0+ are general purpose, used for local variables and parameters; The locations -1 and -2 (in this example) are used for public variables. This is similar to the memory arenas given above, allocating these from the right means we can use the stack memory without causing issues.
Running through the program above, firstly we set stack location 1 to '2' and stack location 2 to '3'. Then we add the value in stack location 1 to stack location 2, putting the result in stack location 1. (I use Intel-style assembly: ADD <destination>, <parameters...>)
CALL tells the VM to call a lookup function in the host program. It will ask that function for the function it should call when it sees the identifier 'sqrt'. If it gets given a function, it will call it.
The function returned by sqrt will look something similar to this:
static void native_sqrt(ModuleInstance *instance, int32_t parameterCount, SVMOperand stack[]) {
stack[0] = sqrt(stack[1]);
}As a convention, the value at 0 in the stack is the return value, and 1+ are the parameters. This gets useful when you consider the following example:
float a = sqrt(2+sqrt(9));Which would compile to something like this:
SET 1, 2
SET 3, 9
STK +2
CALL <sqrt>
STK -2
ADD 1, 1, 2
CALL <sqrt>
MOV -1, 0This one is a little more involved, but it is basically putting the value '3' into stack position 3, then re-numbering the stack so it looks like this:
| nil | 2 | nil | 9 | nil | nil | nil | nil | nil | nil | nil | nil | nil | nil | nil |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | -1 |
The sqrt function (like every function) puts output at position 0 in the stack, so after returning and resetting the numbering, the stack looks like this:
| nil | 2 | 3 | 9 | nil | nil | nil | nil | nil | nil | nil | nil | nil | nil | nil |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | -1 |
So adding the values at 1 and 2 together will produce the desired result.
Almost done... 😪
The second stack is a lot simpler, and is there to let you call functions within the script without losing your place (also letting you sleep the VM). This is exactly the same idea as the call stack, but the fact it exists separately from the host system call stack is what lets you implement the sleep functionality.
| 10 | 32 | nil | nil | nil | nil | nil | nil | nil | nil | nil | nil | nil | nil | nil |
| -1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
Given this call stack, and the code below:
9: PUSHJUMP 31
10: INV 0, 0
31: SET 0, 10
32: POPJUMPWe executed the main code until instruction 9, which told us to push and jump to instruction 31. We incremented the instruction counter to 10, then pushed the value 31 to the stack and continued executing code. The instruction we will execute next (32) will tell us to pop from the stack, at which point the instruction at the top will be 10.
Ok. I'm done with the VM. Sort of. Just one last thing.
Scripting Bindings
I discussed binding functions to the script above a little, but basically you give the VM a lookup function, which will be called when it doesn't know what name a function call refers to. The lookup function look like this:
FunctionCallback scriptingBindingsLookupNativeFunction(uint32_t nameCRC) {
switch (nameCRC) {
case COMPILE_TIME_CRC32_STR("log"): return native_log;
default: return NULL;
}
}This lookup function is currently the only C++ file left in the project. That's because of the COMPILE_TIME_CRC32_STR function, which is a constexpr function I found here: https://stackoverflow.com/a/23683218
(I really wish C would adopt constexpr functions, they're super useful. 😢)
To slightly speed up the lookup of functions the script compiler calculates the CRC32 checksum for the function name, which it passes in here. This lets us do 'string comparison' by integer comparison, which is a lot faster.
Additionally, you can make your own checksum 'key' values for scripts:
if (btn(@"left")) x-=1;In this example, @"left" will be passed as a CRC32 checksum rather than a string. I like this because it lets me use semantic names in scripts, but should keep things fast and reduce the need for having header files full of constants.
Graphics
In a way, deciding how to do graphics for this iteration of the engine was slightly easier because I had the constraint of software rendering. Additionally, because I'm porting a PICO-8 game it made sense to do something similar. There are multiple renderers in the engine as of the moment, but I'm only going to talk about how the PC/Mac renderer works.
To make the window management and graphics device stuff simple I'm using SDL. It's a really great framework to use for software renders as well because getting access to a 'chunk of memory to draw stuff onto' is super simple.
#include <SDL.h>
#include <stdlib.h>
#define generateColor(r, g, b) (r&0xFF) << 0 | (g&0xFF) << 8 | (b&0xFF) << 16 | (0xFF) << 24
int main(int argc, char *argv[]) {
SDL_Init(SDL_INIT_EVERYTHING);
SDL_Window *window = SDL_CreateWindow("title", SDL_WINDOWPOS_UNDEFINED, SDL_WINDOWPOS_UNDEFINED, 640, 480, NULL);
SDL_Renderer *renderer = SDL_CreateRenderer(window, -1, SDL_RENDERER_PRESENTVSYNC | SDL_RENDERER_ACCELERATED);
SDL_Texture *renderTexture = SDL_CreateTexture(renderer, SDL_PIXELFORMAT_ABGR8888, SDL_TEXTUREACCESS_STREAMING, 320, 240);
SDL_Texture *renderTextureIntermediate = SDL_CreateTexture(renderer, SDL_PIXELFORMAT_ABGR8888, SDL_TEXTUREACCESS_TARGET, 640, 480);
SDL_SetTextureScaleMode(renderTextureIntermediate, SDL_ScaleModeBest);
for (;;) {
SDL_Event event;
while (SDL_PollEvent(&event)) {
switch (event.type) {
case SDL_QUIT:
exit(1);
break;
}
}
void *output;
int pitch;
SDL_LockTexture(renderTexture, NULL, &output, &pitch);
uint32_t *pixels = output;
for (size_t y = 0, i = 0; y < 240; ++y) {
for (size_t x = 0; x < 320; ++x, ++i) {
pixels[i] = generateColor(rand()%255, rand()%255, rand()%255);
}
}
SDL_UnlockTexture(renderTexture);
SDL_SetRenderTarget(renderer, renderTextureIntermediate);
SDL_RenderCopyEx(renderer, renderTexture, NULL, NULL, 0, NULL, 0);
SDL_SetRenderTarget(renderer, NULL);
SDL_RenderClear(renderer);
SDL_Rect dstRect = { .x = 0, .y = 0, .w = 640, .h = 480 };
SDL_RenderCopyEx(renderer, renderTextureIntermediate, NULL, &dstRect, 0, NULL, 0);
SDL_RenderPresent(renderer);
}
}I'm not going go too much into the whole design of the rendering backend, it's a little specific, but in general I have created a set of bindings for the scripting language that allow me to use sometime similar to the PICO-8 drawing API.
Lines and Circles
Drawing lines and circles on a software renderer requires you to do it yourself, no help from your graphics card here... But it's pretty much a solved problem at this point. I implemented the Bresenham line and circle drawing algorithms, there's a useful PDF I found about this here: http://members.chello.at/~easyfilter/Bresenham.pdf.
Sprites
For sprites themselves I have opted to simply load directly from the Aseprite data files, using the image decoding methods in the STB headers to decompress when needed. The Aseprite data format is well documented, and I'm hoping this will let me use the metadata contained in these files (regions, animation details) to bypass making some custom tools. It's also worth mentioning that you only have to implement a very limited subset of the data format to get usable data out of the files! I basically only read the images and skip everything else. 😅
Drawing
I'm using 'drawing' here to refer to how to get graphics onto the screen from script. Whatever it should be called, I think it's an interesting thing to discuss.
For this game it's has been fairly easy to decide on a more 'immediate graphics' mode style of drawing, where you call functions to make something draw, rather than (like in something like Unity) associate a sprite/model/whatever with a particular actor.
Most of my scripts work like this:
int x = 0;
int y = 0;
while (true) {
if (btn(@"left")) x-=1;
if (btn(@"right")) x+=1;
circfill(x, y, 32, 8);
line (x-32, y, x+32, y, 7);
sleep;
}Where the logic and the drawing happens at the same time. For this game though, drawing happens on different 'layers', and the order of scripts might not reflect the order of drawing. So to accommodate that, for most of my PICO-8 games, the latest being Factory, I used a draw queue system. Factory was the latest iteration, where I basically dynamically replaced all the PICO-8 drawing functions with versions that would add the draw function and the parameters onto a list.
function draw_queue_replace(fn)
return function(...)
if __draw_queue_depth then
local dq=lget(__draw_queue,__draw_queue_depth)
add(dq,{fn,...})
else
return fn(...)
end
end
end
line=draw_queue_replace(line)
rect=draw_queue_replace(rect)
rectfill=draw_queue_replace(rectfill)
-- etc...For this engine I have done something similar, but in C.
typedef void (*DrawQueueCall)(void *userParameter);
extern DrawQueueID gfxDrawQueueCreate(void);
extern void gfxDrawQueueClear(DrawQueueID drawQueue);
extern MemoryArenaID gfxDrawQueueEnqueueExt(DrawQueueID drawQueue, DrawQueueCall drawCall);The draw queue has a memory arena, and when you enqueue a draw call it returns a memory arena ID that allows you to allocate and set some data relating to that draw call. When the draw call happens, the userParameter for that call is set to point to that data. It's ... functional, but when I've wrapped it up in something for the scripting language I think it'll be close to how the PICO-8 draw queue API works and be fairly seamless.
Closing Notes
- This is not 'how to implement a game engine'
- This is how I am currently working through making a game engine.
- These ideas might not work for you...
- ...but they might do as well.
- There's a lot of stuff missing here...
- ...but it was getting to be a long post.
Making a game engine is hard work, but this year in particular it feels like, for me, it's been worth investing time in making my own tools so that I can explore games on a solid foundation.
I hope it was interesting to read. Feel free to send asks over on Cohost or questions on Mastodon.